What Is Incident Management?
ServiceNow is more than a ticketing system.
It really should be seen as a Platform, or Platform As A Service (PaaS).
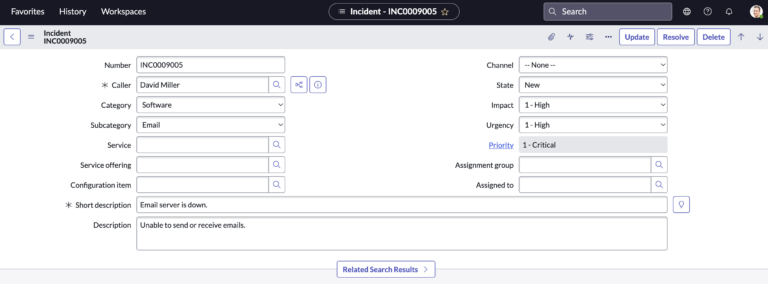
Incident management in ServiceNow is the process of tracking and resolving disruptions or failures that occur in an organization’s IT systems and services. When an incident occurs, it is typically logged as an incident record in ServiceNow. The incident record is used to track the progress of the incident and to coordinate the resolution of the issue.
Incident management in ServiceNow typically includes the following steps:
- Identification: This involves identifying the incident and logging it as an incident record in ServiceNow.
- Classification: This involves classifying the incident based on its severity and impact on the organization.
- Initial Response: This involves taking initial steps to address the incident, such as identifying a workaround or activating an incident response plan.
- Investigation and Diagnosis: This involves identifying the root cause of the incident and developing a resolution.
- Resolution and Recovery: This involves implementing the resolution and restoring the affected systems or services to normal operation.
- Review and Closure: This involves reviewing the incident to determine what can be learned from it and to identify any lessons learned that can be applied to future incidents.
It is the goal of incident management in ServiceNow is to minimize disruptions and improve the overall reliability of the systems by quickly and effectively resolving incidents as they occur.
This is the first post of a 3 article series, where we approach problem management and change management, in more detail.
How Do Incidents, Problems And Changes Work Together?
In ServiceNow, incidents, problems, and changes work together to help organizations track and resolve issues in their IT systems and services.
When an incident occurs, it is typically logged as an incident record in ServiceNow. The incident record is used to track the progress of the incident and to coordinate the resolution of the issue.
There is an entire workflow here in IT Service Management. It goes Incident > Problem > Change.
If the incident is caused by an underlying problem, a problem record may also be created in ServiceNow to track and manage the issue. The problem record is used to identify the root cause of the problem and to develop a resolution.
Once the problem has been identified and a resolution has been developed, the resolution is typically implemented through a change request. The change request is used to track and coordinate the implementation of the resolution, and to ensure that it is tested and reviewed before it is deployed.
Overall, the goal of incidents, problems, and changes in ServiceNow is to help organizations track and resolve issues in their IT systems and services in order to minimize disruptions and improve the overall reliability of the systems.
What Are The Different Priorities Of Incidents?
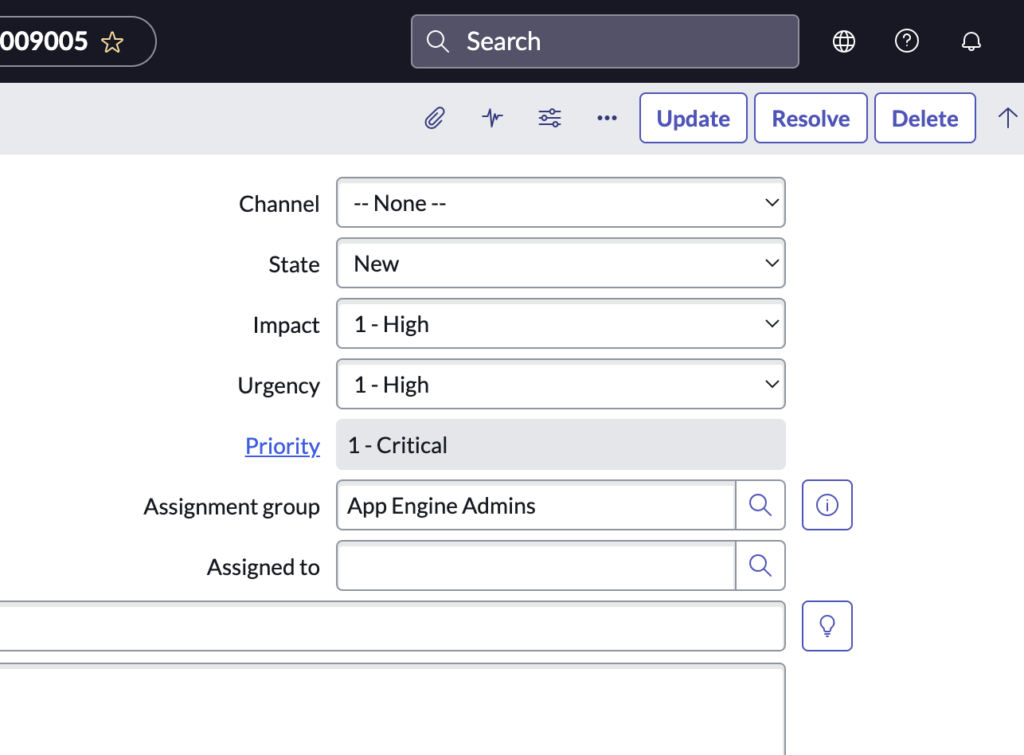
The incident lifecycle is primarily, driven by the priority of the incident.
This dictates your SLA’s on the incident, and determines how long it is acceptable for the incident to be communicated upon, and promptly resolved.
The lower the P1, the more crucial and impacting the priority is to the business.
If you’re an e-commerce company and your website is down – that’s a P1.
If Brenda from accounting can’t get her mouse to work, that’s a P5.
See what we’re saying?
In ServiceNow, incidents are typically classified based on their severity and impact on the organization. The specific priorities for incidents will depend on the organization’s policies and procedures, but some common priorities are:
- P1 – Critical: This priority is used for incidents that have a significant impact on the organization and require immediate attention. Examples of critical incidents might include a complete system outage or a security breach.
- P2 – High: This priority is used for incidents that have a significant impact on the organization but are not as urgent as critical incidents. Examples of high priority incidents might include a partial system outage or a major issue with a mission-critical service.
- P – 4 Medium: This priority is used for incidents that have a moderate impact on the organization. Examples of medium priority incidents might include a minor issue with a non-critical service or a problem that can be worked around.
- P -5 Low: This priority is used for incidents that have a minimal impact on the organization. Examples of low priority incidents might include a request for information or a minor issue that does not significantly impact the operation of the systems or services.
This a general guideline.
Some companies have 5 or 6 priorities.
We’re not going to fight you on that – that’s up for you to decide.
If you’d like to learn more about how priority is calculated, check out the impact and urgency matrix article here.
The priority of an incident in ServiceNow is used to determine the level of resources and attention that should be dedicated to resolving the issue.
What Happens When A P1 Incident Is Created?
P1’s happen at every company.
Do you have a solid and agreed upon plan in place, for when they do happen?
This is something that a surprising number of companies, don’t have established.
If you don’t have one, you need to add it to your ServiceNow roadmap ASAP.
When a P1 (critical) incident is created in ServiceNow, it is typically considered a high-priority issue that requires immediate attention. The specific process for responding to a P1 incident will depend on the organization’s policies and procedures, but some common steps might include:
- Activation of an incident response plan: This might involve activating a pre-defined plan for responding to critical incidents, which may include identifying a response team, activating backup systems or services, and coordinating with relevant stakeholders.
- Notification of relevant parties: This might involve alerting key personnel, such as IT staff, senior management, and affected users, about the incident and the steps being taken to resolve it.
- Initial response: This might involve taking initial steps to address the incident, such as identifying a workaround or activating backup systems or services.
- Investigation and diagnosis: This might involve identifying the root cause of the incident and developing a resolution.
- Resolution and recovery: This might involve implementing the resolution and restoring the affected systems or services to normal operation.
- Review and closure: This might involve reviewing the incident to determine what can be learned from it and to identify any lessons learned that can be applied to future incidents.
P1’s happen at every company, if you’re prepared – they will be a lot less stressful.
The goal of responding to a P1 incident in ServiceNow is to minimize disruptions and restore normal operation as quickly as possible. The process for alerting people about a P1 incident will depend on the organization’s policies and procedures, but it might involve using an automated notification system, such as email or text message alerts, to inform key personnel about the incident and the steps being taken to resolve it.
What Are Popular On-Call Tools For P1 Incidents?
All of these tools integrate nicely into ServiceNow.
Let’s dive into a few really popular incident alert management tools.
These are software tools that will manage, call and text message your engineers, when they’re on-call – if a P1 were to ever come up.
There are a number of incident alerting tools that can be used to notify people by text or call when a P1 (critical) incident is created in ServiceNow. Some popular options include:
- PagerDuty (www.pagerduty.com): This is a cloud-based incident management platform that offers a range of notification options, including SMS, phone, and push notifications.
- VictorOps/Splunk On-Call – Acquired by Splunk (www.victorops.com) or (https://www.splunk.com/en_us/products/on-call.html): This is an incident management platform that offers a range of notification options, including SMS, phone, and integrations with messaging platforms like Slack.
- xMatters (www.xmatters.com): This is an incident management platform that offers a range of notification options, including SMS, phone, and integrations with messaging platforms like Slack and Microsoft Teams.
- AlertOps (www.alertops.com): This is an incident management platform that offers a range of notification options, including SMS, phone, and integrations with messaging platforms like Slack and Microsoft Teams.
We don’t have any preference in any of the above, and we’ve integrated and used them all.
It’s not an absolute necessity to have an alerting tool for P1’s but it sure does help.
If you have any experience with the above vendors, we’d love to hear what you have to say in the comments.
These tools are designed to help organizations quickly and effectively notify the appropriate parties about critical incidents, enabling them to respond and resolve the issues as quickly as possible.
That’s about all we have to say, so far, on incident management.
Take a look at our problem management overview, if you’d like to understand more about IT Service Management.
If we didn’t cover something about incident management, please let us know below.